
Words at a party: The simple idea behind how LLMs really work
A math-free explanation of attention

In 2017 a team of Google engineers published a paper called “Attention is all you need.” If there’s one moment you can point to as the spark of our current AI revolution, this paper is it. In it, the authors propose a new neural network for understanding text called a Transformer, which is what all modern LLMs are now based on. At the heart of a Transformer network is what the researchers called the attention mechanism, hence the title of their paper. The attention mechanism is often presented as a device which computes a complex mathematical formula. In this post I’ll pull back the curtain and give a non-technical description that conveys what’s really going on.

First, you need to understand that the purpose of the attention mechanism is to decide the importance of every word in a sentence for the meanings of the other words in that sentence, i.e. which words each word pays “attention” to. For example, in the sentence, “The ball rolled off the blue table”, the words ball and table are important referents for the word rolled. They answer questions like “what rolled?” and “where did it roll?”. The word blue is probably not as important for understanding the context of rolled. On the other hand, the word blue may be an important descriptor for table.
To explain the attention mechanism I’ll use an analogy, where we’ll replace words with people at a party. Each person knows they will have a limited amount of time there, and will have to decide, in advance, how much time they want to spend chatting with each of the other attendees.
Now, this isn’t just any party. This is a party for travel enthusiasts. Each attendee is interested in learning about what life is like in many different countries. Each person has also been to many countries, and learned things about what it’s like to live in those places. The only complication is that the things they have learned are all muddled together in their heads, so they can’t say what they learned where. However, if you talk to a bunch of people who have only been to Mediterranean countries about what they know about cooking, you can get a pretty good idea of what Mediterranean cuisine is like.
Let’s give an example. Suppose the attendees at this party are 1970’s TV characters: Mork, Fonz, Archie, and Hawkeye. The table below tells us where each of these people has been, and where they want to learn more about.
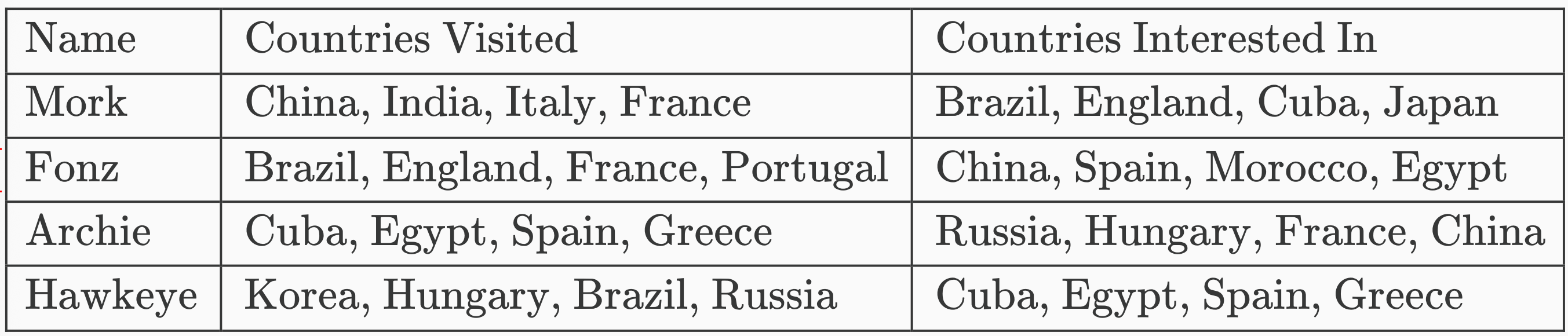
Before attending the party, each person receives a list of which countries every other person has been to, i.e. the first two columns in the above table. It’s this list they are going to have to use to decide who to talk to at the party, and how much time they want to spend with each of those people, talking about the things they’ve learned on their travels.
Let’s talk about Mork first. He’s interested in learning about life in Brazil, England, Cuba and Japan. Fonz has been to two of those countries. Archie and Hawkeye have each been to one of those countries. So Mork is going to want to talk to all three of the other attendees, but spend twice as much time with Fonz as he will with Archie or Hawkeye. He can do this by spending 50% of his time with Fonz, 25% with Archie, and 25% with Hawkeye.
Now let’s talk about Hawkeye. He’s interested in learning about Cuba, Egypt, Spain, and Greece. Neither Mork nor Fonz has been to any of those, but Archie has been to all four. So Hawkeye is going to want to spend 100% of his time talking to Archie, and 0% of his time talking to the other two.
How does this relate to the attention mechanism in Transformer models? We’re ready for that mathematical formula I mentioned earlier that the attention mechanism computes:
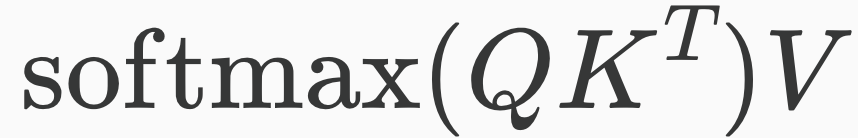
Here’s how to understand this with the party analogy. The “people” at the party are the words in the sentence we’re trying to understand. The countries they are each interested in is a vector called the queries, represented here by the letter Q. The countries that they have each been to are the keys, represented by K. The product QK^T (where T stands for “transpose”) is where each person compares the countries they’re interested in to the places every other person has been to, and the softmax function converts those scores to percentages. Finally, the stuff each person knows about is what is represented by the value vector, V.
How do transformer models assign separate query, key and value vectors to each word in the sentence? Initially this is done completely randomly. However, as the model is fed more and more training data it adjusts those vectors automatically (through a process called backpropagation) so that, over time, the model becomes better at whatever task it’s designed for. This may be a “sentiment analysis” task, where the purpose of the model is to decide if the sentence is conveying something positive or negative. Or, more commonly these days, it may be a “next token prediction” task, where the model is trying to predict a missing word at the end of a string of words.
That’s really 80% of the way to understanding Transformer models, and hence all modern LLMs! The remaining 20% comes from understanding how transformer models use the position of each word to understand the role they play in a sentence, because the attention mechanism (as I’ve described it) treats them as being at a party in no particular order. So far we’ve only given each partygoer a sense of who to talk to. In a future post we’ll give them a sense of where they’re sitting.
David Bachman is a professor of Mathematics, Data Science, and Computer Science. To learn more about David’s work, visit his AI speaking and consulting site, his faculty page, or explore his mathematical art portfolio.